
通义千问开源 Qwen15 六大版本:性能仅次于 GPT-4 Turbo |AI 鲜测


春节前夕,通义千问时隔三月发布了 Qwen 模型的最新版本 Qwen1.5。

新版大模型开源了六个型号尺寸:0.5B、1.8B、4B、7B、14B 和 72B。
以下是此次更新的一些重点:
- 支持 32K 上下文长度;
- 开放了 Base + Chat 模型的 checkpoint;
- 可与 Transformers 一起本地运行;
- 同时发布了 GPTQ Int-4 / Int8、AWQ 和 GGUF 权重。
先不看跑分,硅星GenAI上手试了试,看看它跟前代(1.0 版本)、GPT-3.5 和 GPT-4 实测对比效果:
这些测试包含如数学、逻辑、文字理解的相关问题。
首先,是两道数学题:
- 概率问题:一个标准的六面骰子连续掷两次,第一次掷出6的概率是多少?(正确答案:1/6)
- 代数问题:如果一个数加上它的倒数等于10/3,求这个数?(正确答案:1/3 或者 3)
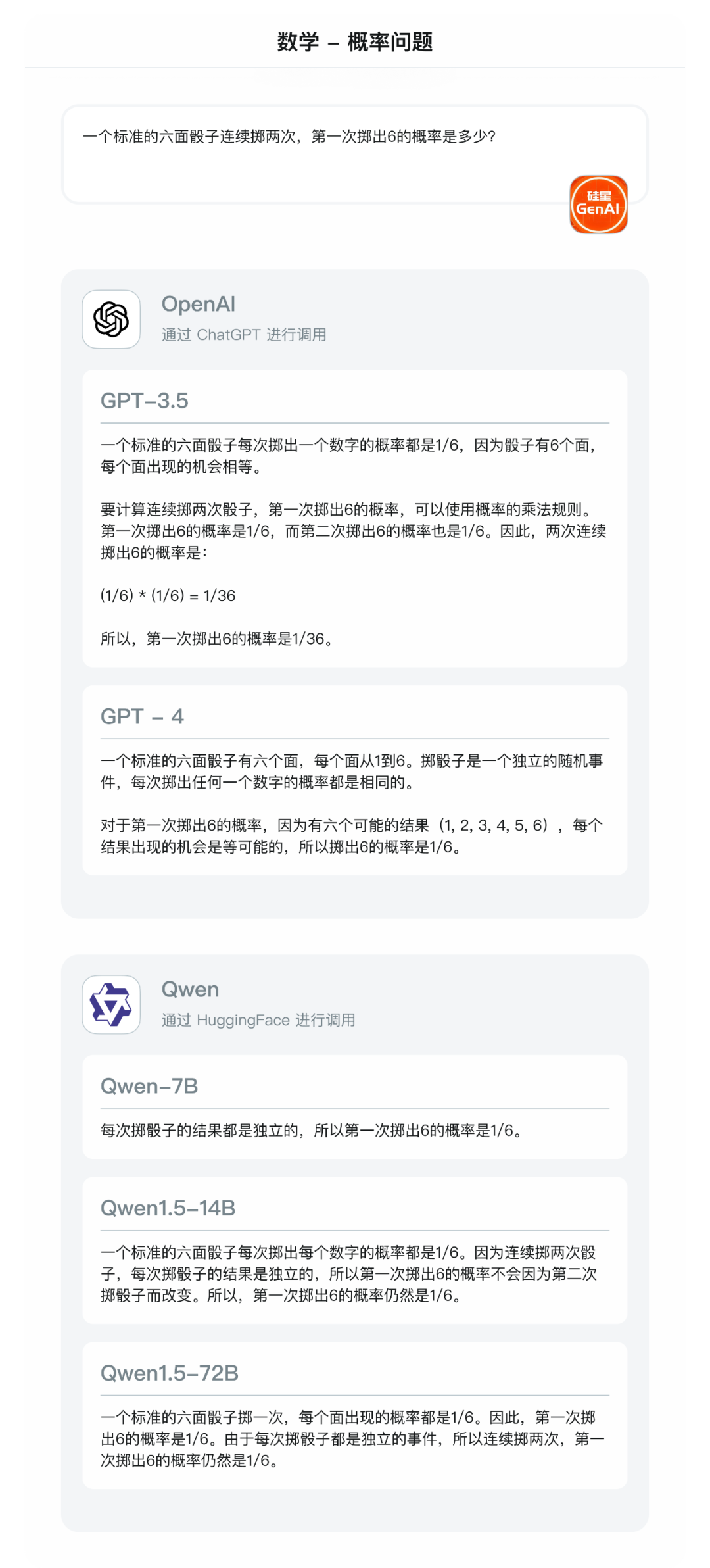
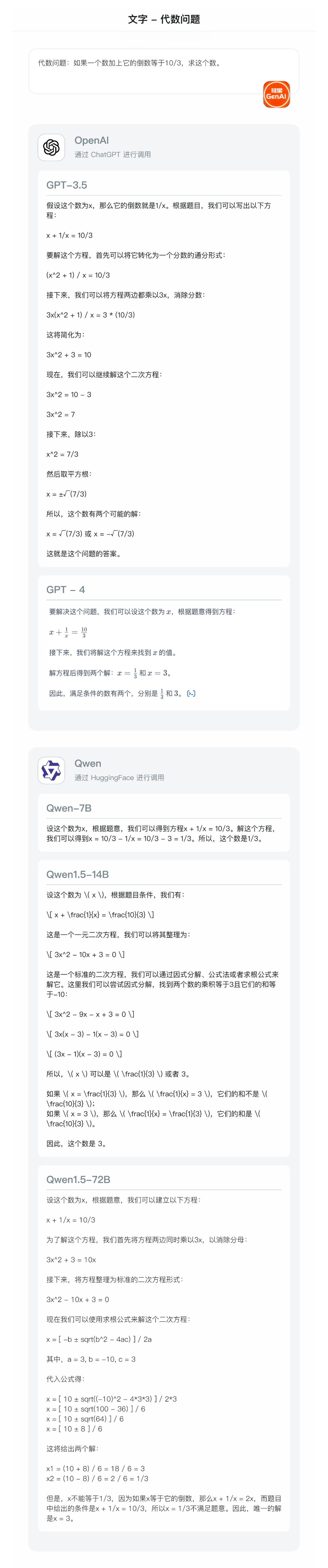
无论是Qwen1.0,还是Qwen 1.5,其数学能力都超过了 GPT-3.5,给出了准确的思考过程。但 GPT-4 更胜一筹,能给出最为准确的答案。
接着,是两道逻辑题:
- 抽象推理:A比B大,C比A大,D比C小。如果E比D大,那么最小的是?(正确答案:B)
- 条件逻辑:如果下雨,我就不去公园。如果我去了公园,是否可以推断当天没有下雨?(正确答案:可以推断,并且当天没有下雨)
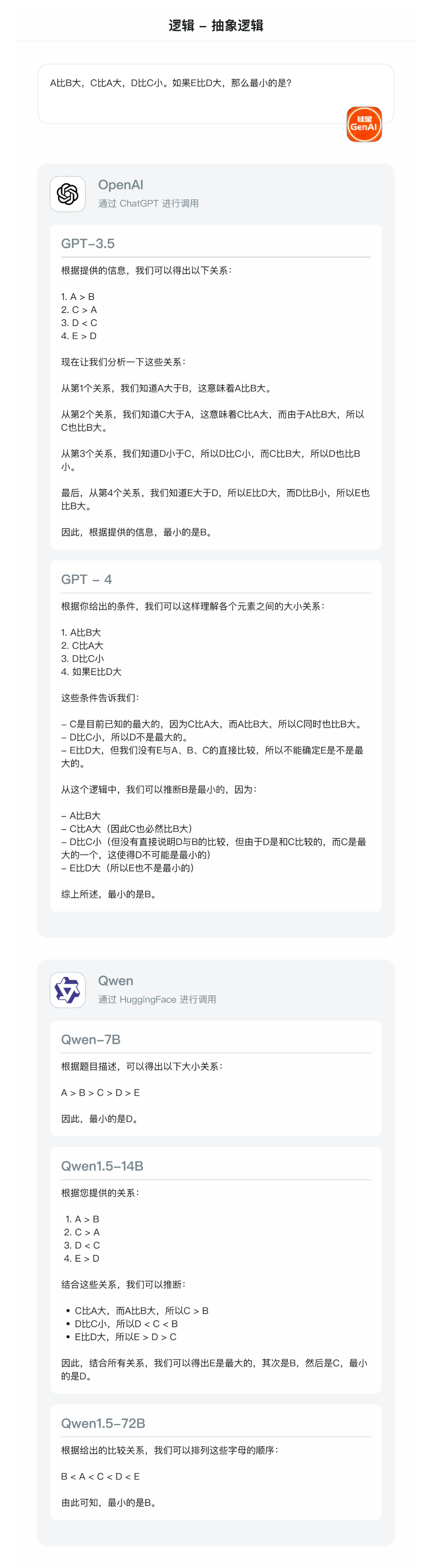
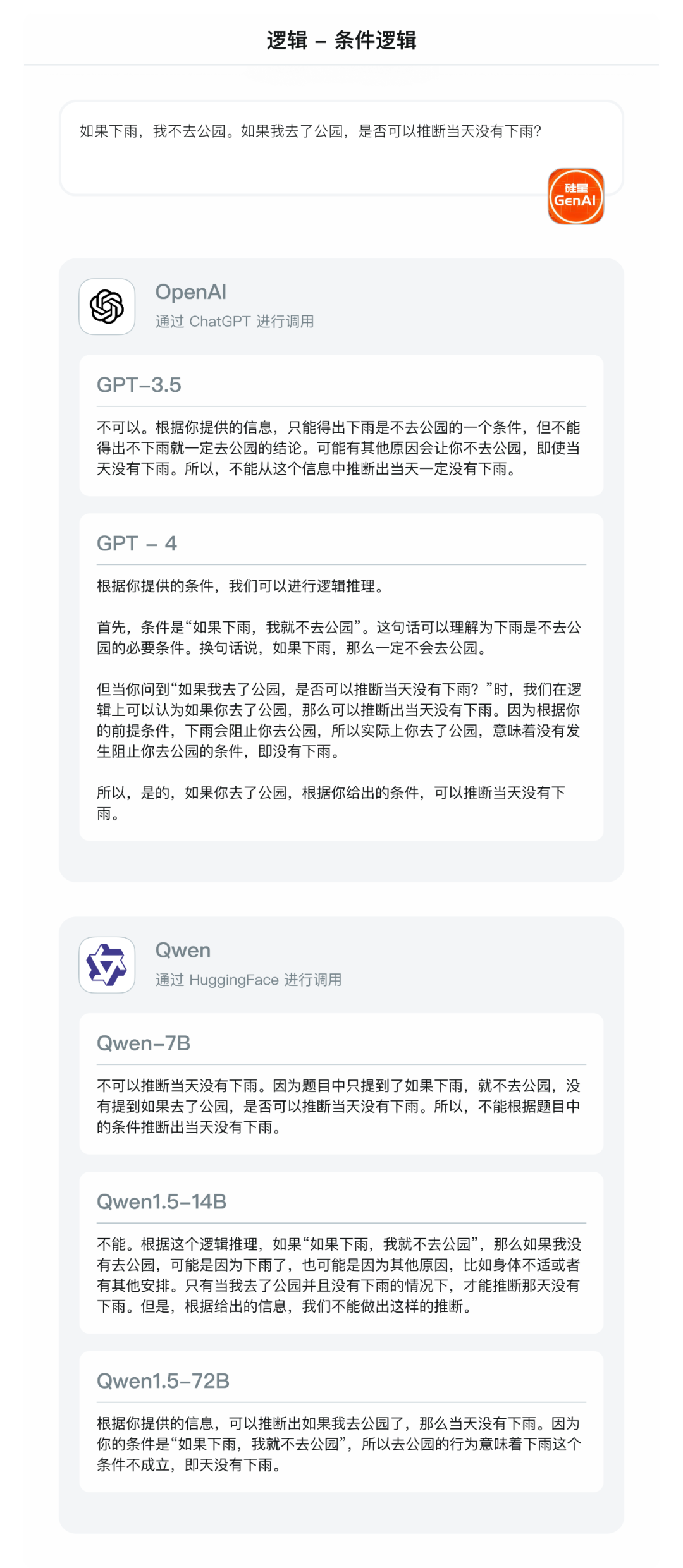
看得出,无论是 GPT,还是 Qwen 的模型,对于简单逻辑(比大小)都可以进行很好的处理;
但对于复杂逻辑判断,只有 GPT-4 以及 Qwen1.5-72B 可以做出准确处理。
最后,是两道文字题:
- 文本分析:分析以下句子的意图和情感:“虽然外面的风雨如磐,但他依然决定继续前行。”
- 隐喻和比喻:在“时间是一条河流,我们是河中的游鱼”的比喻中,时间和人的关系是如何被描述的?
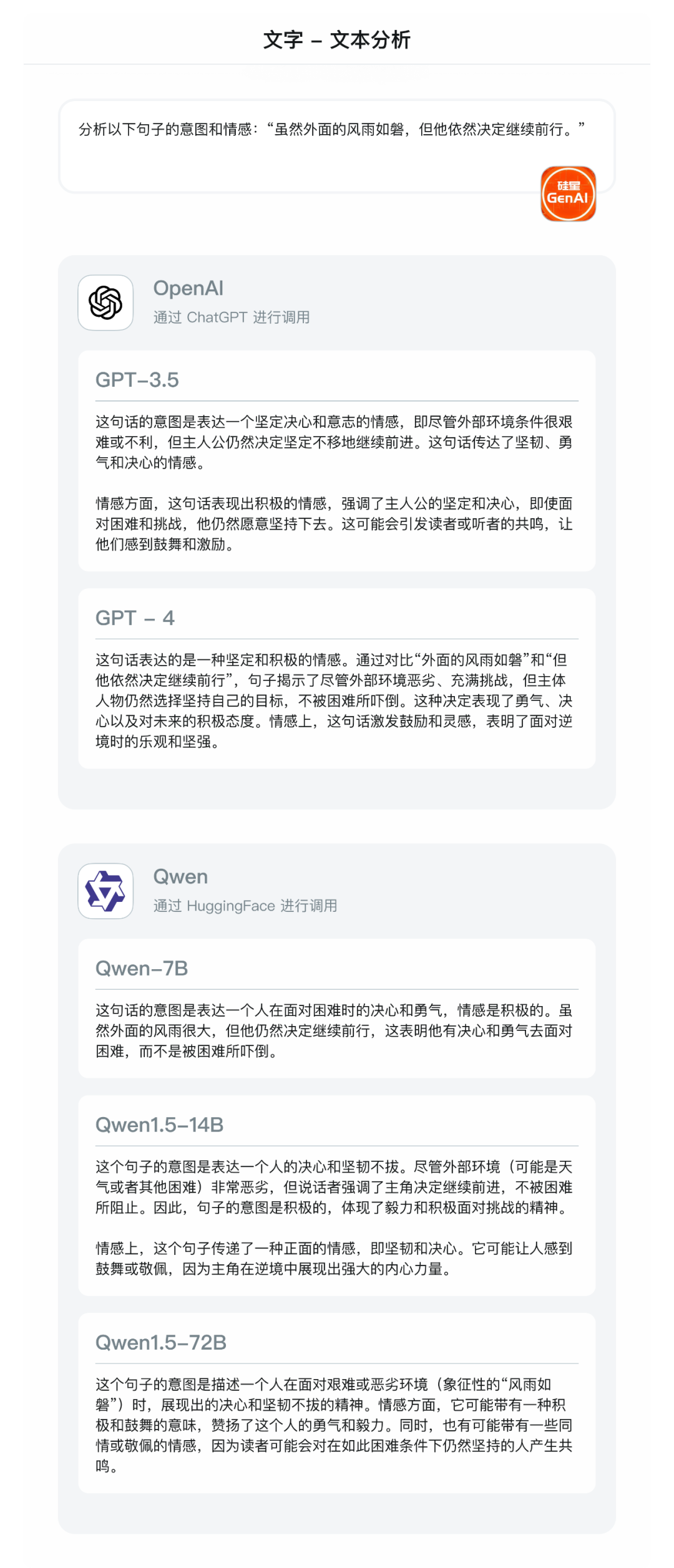
在这一题中,Qwen1.5-72B 竟然从中领悟到了“同情”和“敬佩”的感情,这是其他模型,甚至是我自己都没想到的点,而且细想确实有道理。
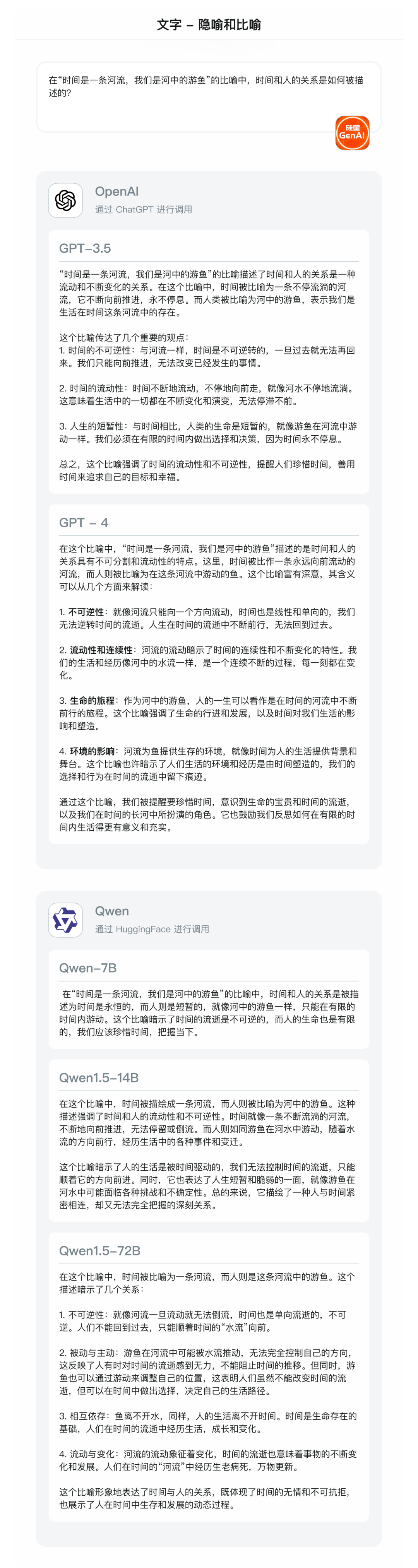
论鸡汤,我觉得还是 Qwen1.5 72B 说的最有道理。整体来看,在 GPT系列模型中,面对此问题是一种消极的态度。
而 Qwen1.5 则是一种相对积极的观点——虽然我们无法左右时间前后,但可以自己调整身位来决定自己的生活路径。
性能测试与解读

在 MT-Bench 和 Alpaca-Eval v2 上,Qwen1.5-72B-Chat 表现不错,虽然不如 GPT-4 Turbo,但超过像是 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B在内的一众模型,与 Mistral Medium 基本持平。
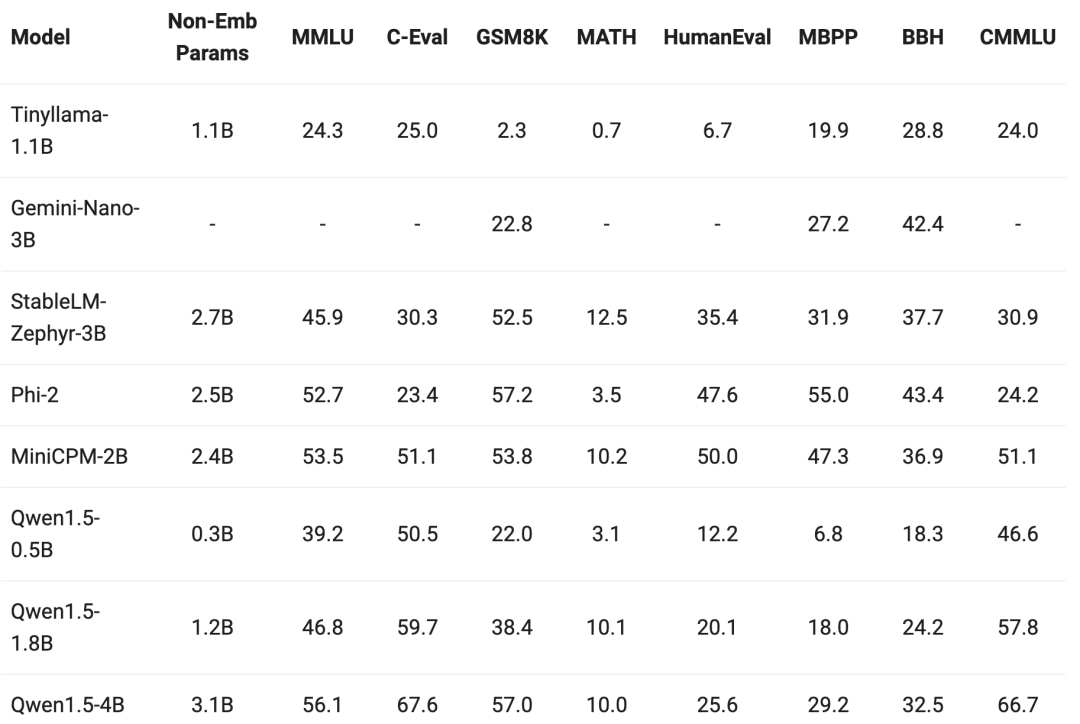
在小模型的测试中,这次在 7B 以下的 Qwen1.5 版本,都表现不错。
目前,Qwen1.5 已经与 HuggingFace transformers 代码库进行了集成。从 4.37.0 版本开始,开发者可以直接使用 transformers 库原生代码,而不加载任何自定义代码(指定 trust_remote_code 选项)来使用 Qwen1.5。